On parle beaucoup d’intelligence artificielle. De ses usages, de ses promesses, de ses risques. Plus rarement des sciences de la donnée qui la rendent possible — et encore moins de ce qu’elles font à nos manières de décider et de gouverner.
Les sciences de la donnée constituent les fondations techniques des systèmes data & IA. Mais elles ne suffisent pas à structurer la décision dans les organisations.
👉 Cette question est abordée dans notre guide dédié à l’architecture décisionnelle.
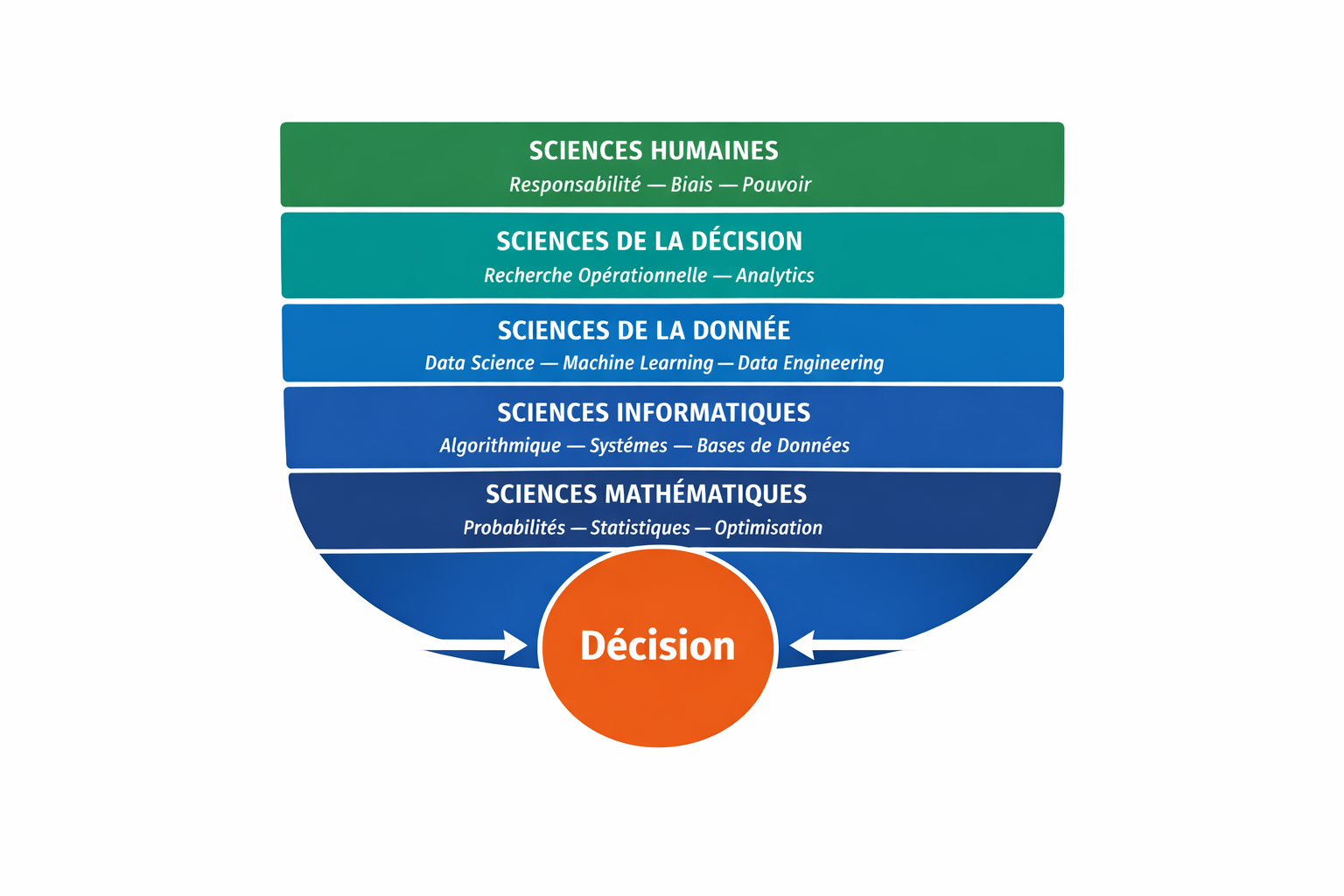
Derrière l’IA, il n’y a pas une entité autonome, mais un empilement de sciences : mathématiques, statistiques, informatique, sciences du traitement de la donnée, sciences de la décision. Des sciences qui transforment le réel en données, les données en modèles, et les modèles en options d’action.
Les sciences mobilisées par les systèmes data et IA.
L’intelligence artificielle ne repose pas sur une seule discipline, mais sur un empilement de sciences qui rendent la décision calculable, observable et parfois automatisable.
Des mathématiques qui modélisent l’incertitude, à l’informatique qui rend les calculs possibles à grande échelle, en passant par les sciences de la donnée qui produisent des modèles et les sciences de la décision qui orientent l’action.
Les sciences humaines, enfin, rappellent que ces systèmes ne fonctionnent jamais hors des collectifs, des responsabilités et des rapports de pouvoir.
Ce schéma ne cherche pas à figer les frontières entre disciplines. Il montre simplement que la décision augmentée par la donnée repose sur un ensemble de sciences qui se superposent et se répondent.
Poser les sciences de la donnée, ce n’est pas chercher l’exhaustivité ni produire une cartographie figée. C’est accepter de regarder les coulisses : les cadres intellectuels, les hypothèses implicites, les choix de représentation qui orientent silencieusement ce que l’on voit — et ce que l’on ne voit pas.
Cette question est indissociable de celle de la gouvernance de la donnée. Non pas au sens d’une appropriation ou d’un inventaire exhaustif — souvent illusoire dans des systèmes complexes — mais comme une attention portée aux flux de données : là où elles circulent, se transforment, s’anonymisent, produisent (ou non) un impact réel pour les équipes, les produits et les décisions.
Dans les organisations, la donnée n’appartient jamais vraiment à quelqu’un. Elle traverse les métiers, les systèmes, les outils. Chercher à en être “propriétaire” relève souvent davantage de jeux de pouvoir que d’une gouvernance effective. Suivre les flux, en revanche, permet de relier le développement aux usages, les métiers aux clients, et les décisions aux effets observables.
Cet article n’a pas vocation à expliquer l’IA ni à prescrire une méthode. Il ouvre un espace de réflexion sur les fondations scientifiques qui structurent nos environnements décisionnels, et sur la manière dont la donnée peut redevenir un appui pour décider — plutôt qu’un prétexte pour diluer la responsabilité.
Dans l’esprit du Campus, ce texte est volontairement vivant. Il évoluera au fil de l’année, en fonction de l’actualité, des débats émergents, des transformations observées sur le terrain. Les sections qui suivent ouvrent des champs de pensée. Elles seront enrichies, précisées, parfois déplacées, à mesure que le Campus continue d’explorer ce que décider, livrer et gouverner veulent dire à l’ère de la donnée et de l’IA.
➡️ “Comment stocker, traiter et faire circuler la donnée à l’échelle ?”
Ce qu’il est important de noter c’est que l’IA est d’abord algorithmique pour gérer la complexité. Cela permet : Structures de données, graphes, heuristiques ➡️ “Comment transformer un problème en procédure calculable ?”
Cela permet notamment d’analyser : signal, bruit, compression, entropie… Pour répondre à la question : ➡️ “Qu’est-ce qui constitue réellement de l’information dans un flux de données ?”
C’est très pertinent pour parler :
des LLM.
de qualité de donnée
de signal vs bruit
Les sciences de la donnée : traitement et exploitation
Ici c’est le prolongement mathématique ou les sciences de l’ingénierie qui permettent de rendre la donnée exploitable, et résoudre des problèmes associés
La data science et l’ingénierie des données sont deux domaines interconnectés qui explorent l’utilisation des données pour résoudre des problèmes et générer des informations exploitables.
Exploration de données
Modélisation statistique
Visualisation
Expérimentation
➡️ “Qu’est-ce que les données racontent vraiment ?”
KPI , voir notre série Déambulations de Romain qui montre comment un étudiant charche à comprendre les indicateurs de performances et les indcateurs de valeurs.
Mesure de valeur
Expérimentation produit
Pilotage stratégique
➡️ “À quoi sert la donnée pour l’action ?”
Les sciences humaines et sociales autour de la donnée
Parce que les organisations ne sont pas des machines de calcul, a décision implique notamment :
responsabilité
cognition
perception
biais
pouvoir
C’est pourquoi les sciences humaines sont impliquées.
Gouverner : science de l’architecture décisionnelle
Gouverner ne consiste pas à décider à la place. Gouverner consiste à concevoir et expliciter l’architecture dans laquelle les décisions deviennent possibles, responsables et cohérentes.
Dans un environnement data & IA, gouverner signifie :
définir les lieux d’instruction (données, modèles, outils),
clarifier les lieux d’arbitrage,
expliciter les responsabilités,
organiser les boucles d’impact,
aligner usage, valeur et responsabilité.
Gouverner est donc une fonction transversale :
aux mathématiques (fiabilité des modèles),
à l’informatique (robustesse des systèmes),
à l’exploitation (qualité des flux),
à la décision (arbitrage),
aux sciences humaines (comportements, pouvoir, culture).
Les sciences de la donnée rendent les modèles possibles. Mais elles ne disent pas comment les décisions doivent être portées dans l’organisation.
Cette question est approfondie dans notre page dédiée à l’architecture décisionnelle à l’ère de l’IA, qui explore comment organiser les lieux d’instruction, d’arbitrage et de responsabilité dans des systèmes décisionnels augmentés par la donnée.